
Category: experiments
-
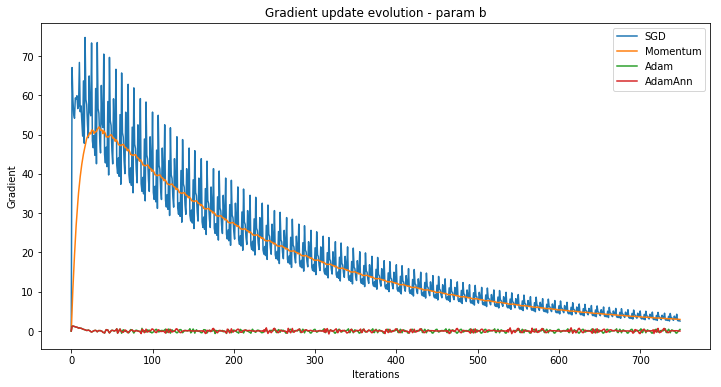
Visualising SGD with Momentum, Adam and Learning Rate Annealing
Watch optimizers battle it out in a visual showdown—Momentum vs Adam vs LR schedules, explained with intuition and flair.
-

What Are The 10 Most Cited Websites On Twitter When Tweeting About Hot Trends?
Scrapes and analyzes tweets around Google Hot Trends to see which domains dominate the conversation.
-

How To Build A Relevant Real Time Search Engine Prototype In Few Hundreds Lines Of Code
A hands‑on blueprint for a lightweight, low‑latency (toy) search engine that ingests and surfaces fresh content fast.
-

Drawing A Zipf Law Using Gnuplot, Java and Moby-Dick
Let’s use the Moby‑Dick text to generate word frequency plots and illustrate Zipf’s law programmatically.
-
Google Hot Trends Clustering: The 100 Hottest Queries Tell You About 67.76 Stories In Average
Did you noticed that among the 100 (hourly updated) Google Hot Trends, there are always several hot queries that are related one to the other? Let’s take a look at the Hot Trends of the current hour by the time I’m writing this post: Hot Trends of September 24 at 11PM PST Time (clicking on…
-
Can You Guess What Is The Hottest Trend Of Google Hot Trends ?
Either if you are working in SEO, or if you are a “trends hacker”, or if you love like me doing useless comparisons like hanukkah vs passover, you obviously know the fantastic google trends tool. I’m even more fascinated by the google hot trends functionality that shows the 100 hottest English queries typed in the…