
Category: Uncategorized
-
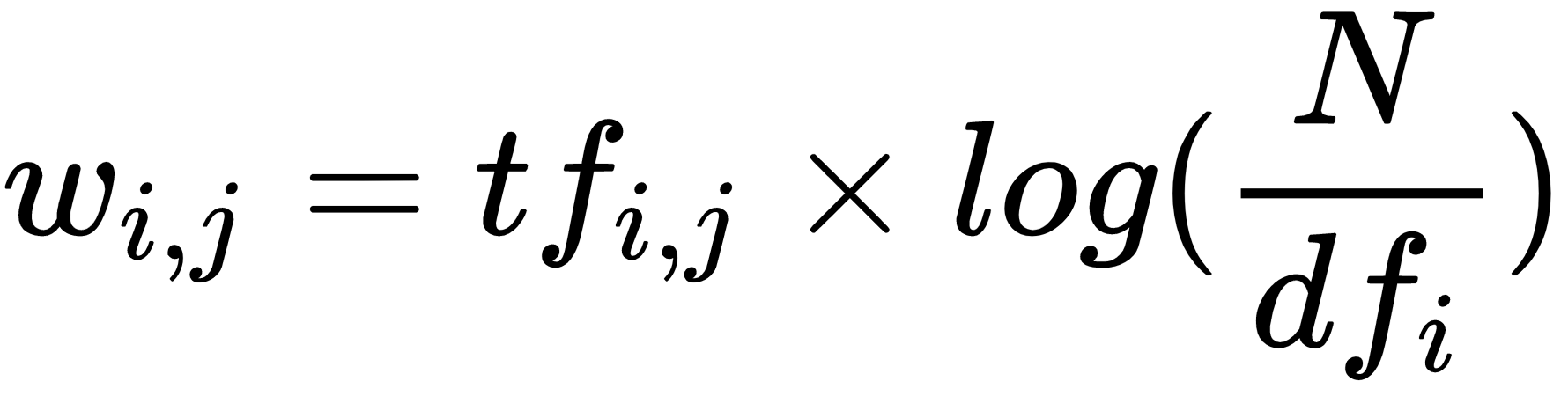
How To Easily Build And Observe TF-IDF Weight Vectors With Lucene And Mahout
Want to peek inside TF-IDF weights? Here’s a quick way to build and analyze them without the headache.
Want to peek inside TF-IDF weights? Here’s a quick way to build and analyze them without the headache.