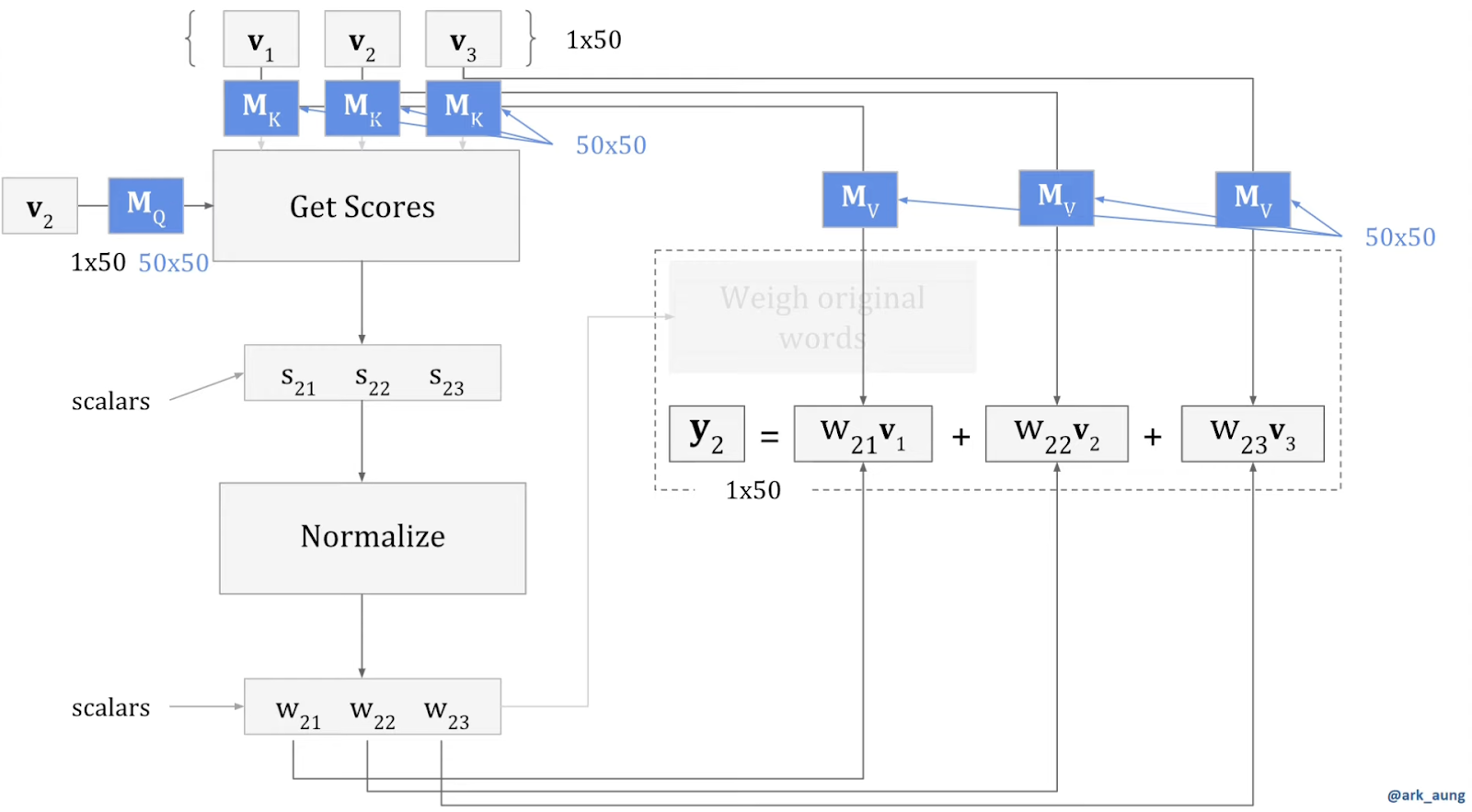
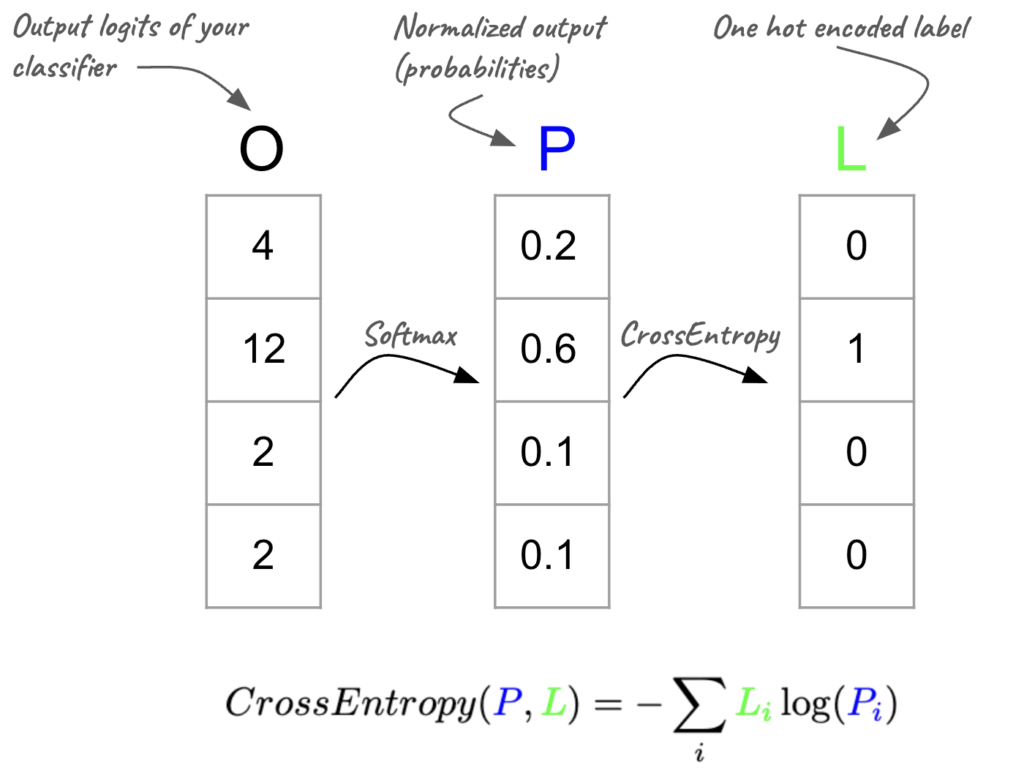
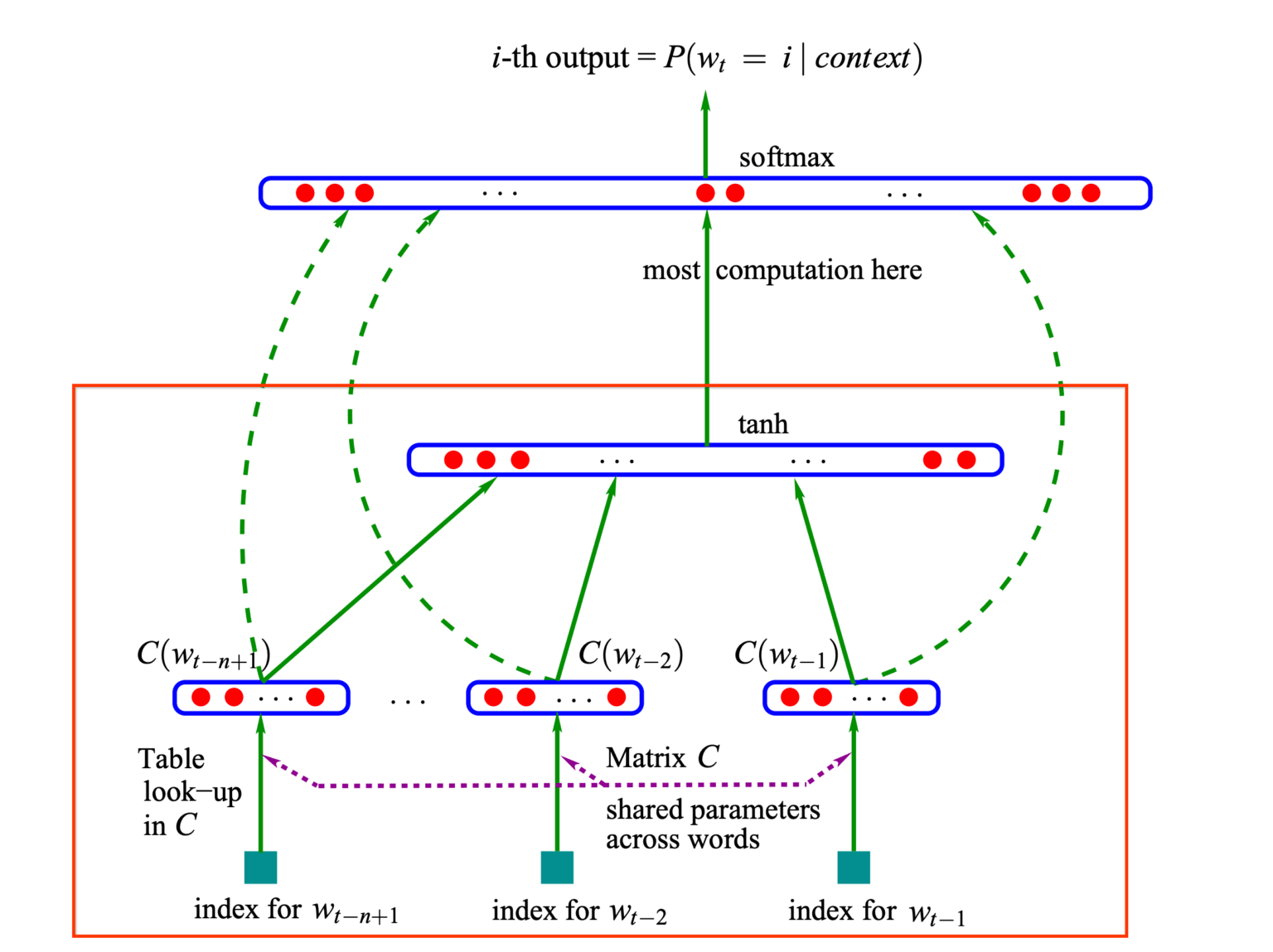
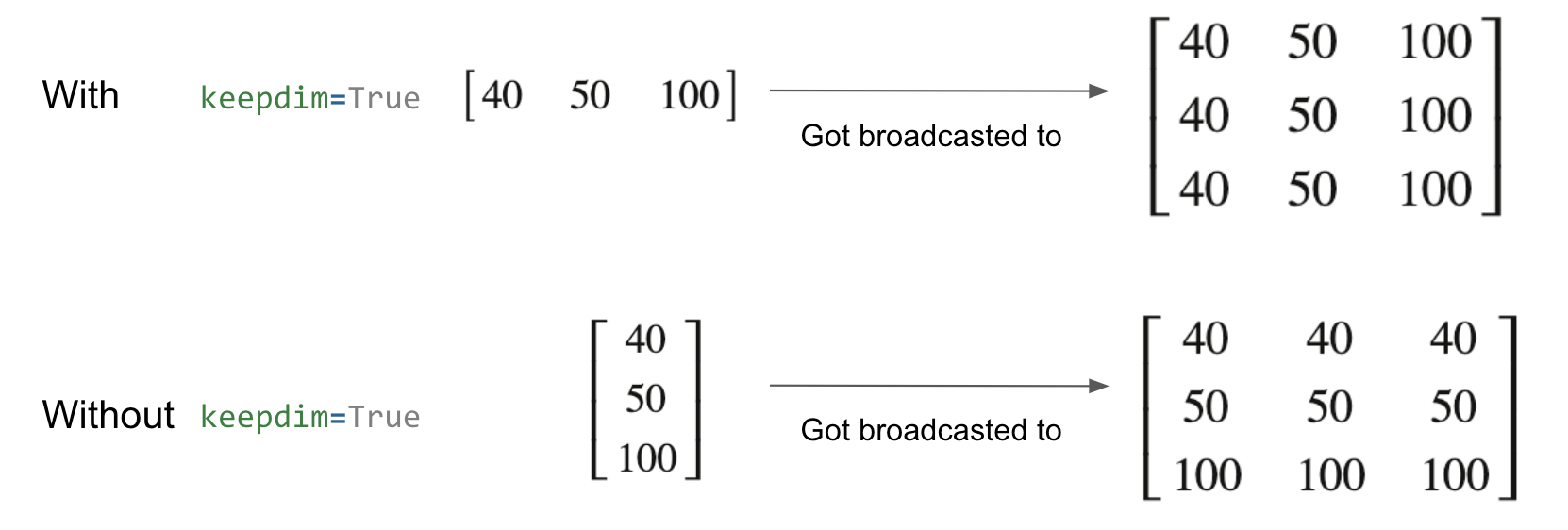
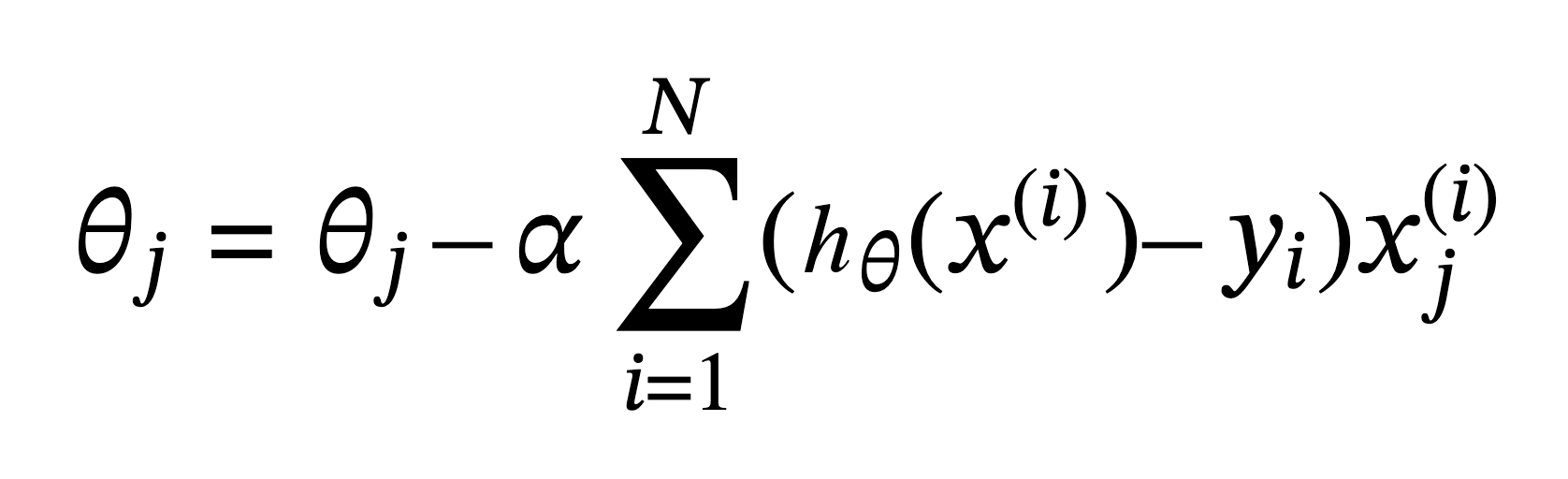Self Attention is the heart of Transformers, the T of GPT. But there are few additional critical parts to the transformer architecture that actually made it shine.
The simplest model we can use to predict the next character is a Bigram Model. But if implemented as a neural net, the building blocks will stay the same up to GPT.
Don’t understate the importance of building a proper training set. It is a critical part of the process, and in GPT’s case, a beautifully cleaver one as well.
In this third and last post of this series, we present the use of a very effective and powerful library to build logistic regression models (among others) in practice: Vowpal Wabbit.
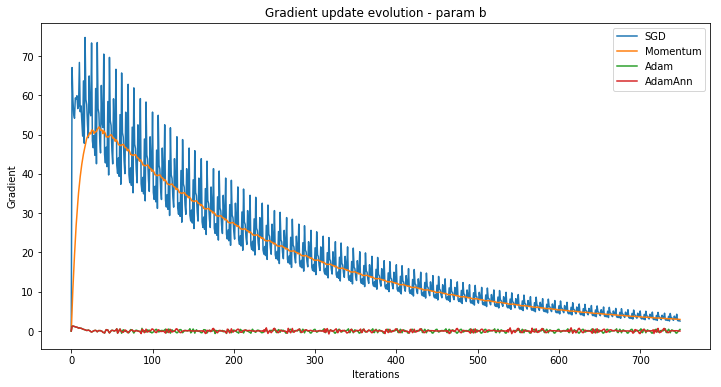
Want to know how to implement Stochastic Gradient Descent for Logistic regression able to learn millions of parameters using the hashing trick and per-coordinate adaptive learning rate with a tiny memory footprint? This post is for you.